SparkCore 中的工作原理 - 任务执行流程 5.1

| – | – | – | – |
|---|---|---|---|
| application | job | stage | task |
| master | worker | executor | driver |
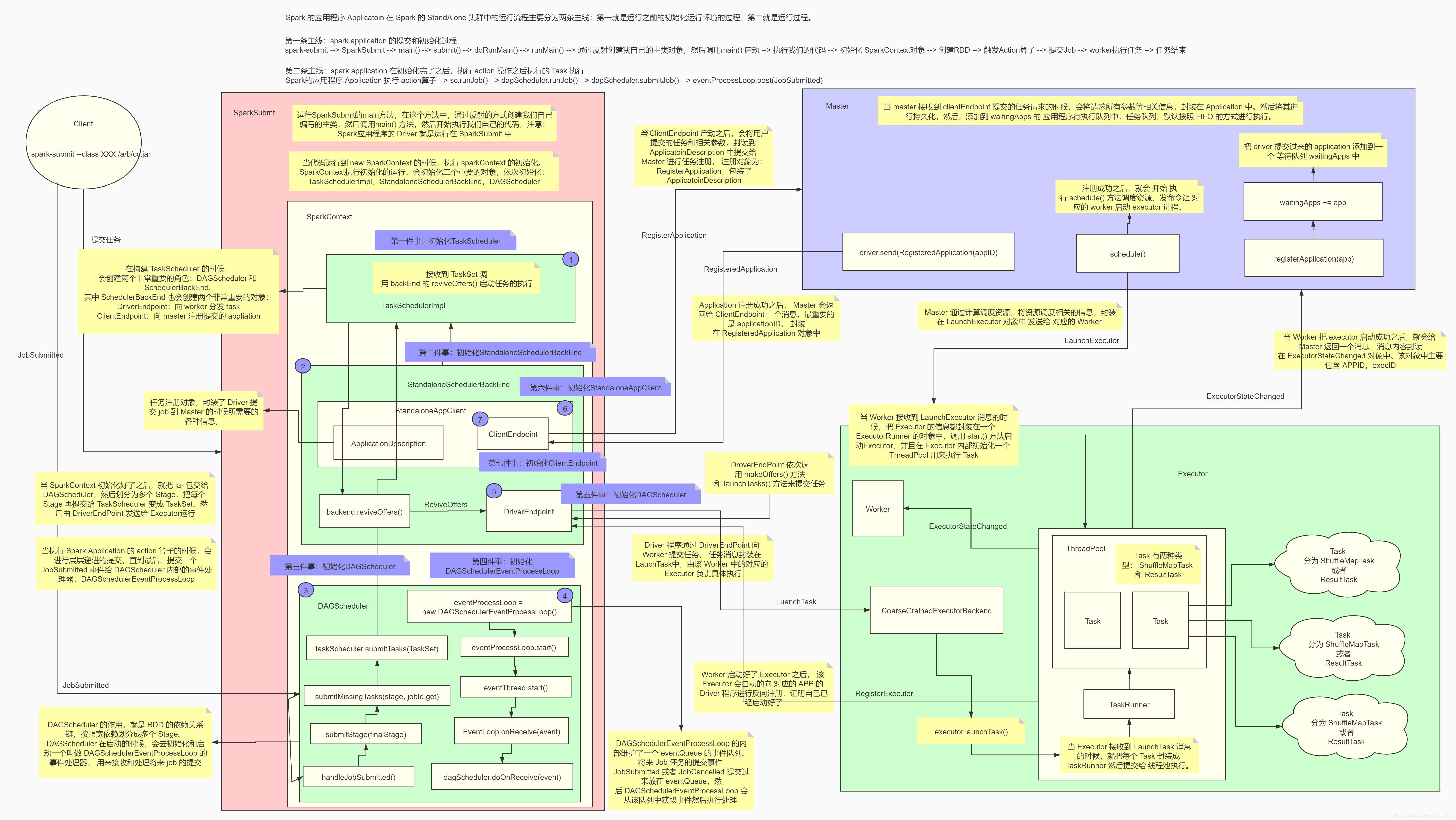
整个 Spark 应用程序的运行分成三个阶段:
1). 编写代码,使用 spark-submit 去交任务到集群运行,一直到我们自己编写的main方法运行为止
1.1) 编写代码
1.2) 打成 Jar
1.3) 编写 spark-submit 脚本提交任务
1.4) 脚本解析 和 执行 最终转到 main 方法执行 SparkSubmit
2). sparkContext 的初始化
new SparkContext(sparkConf)
两条线:
(1) 在 driver 端执行的代码
- init TaskScheduler ----> TaskSchedulerImpl
- init SchedulerBackend ----> StandAloneSchedulerBackend
- init DAGScheduler ----> DAGScheduler
(2) 在 worker 和 master 端执行的各种代码
业务功能实现:
- 1、 master 注册
- 2、 worker 负责启动 executor
3). action 算子
1. SparkSubmit
| No. | Spark 任务的提交流程 |
|---|---|
| (1) | 首先将程序打成 jar 包 |
| (2) | 使用 spark-submit 脚本提交任务到集群上运行 |
| (3) | 运行 sparkSubmit 的 main 方法,在这个方法中通过反射的方式创建我们编写的主类的实例对象,然后调用 main 方法,开始执行我们的代码(注意,我们的 spark 程序中的 driver就运行在 sparkSubmit 进程中) |
2. SparkContext 初始化
| No. | SparkContext 初始化 |
|---|---|
| (4) | 当代码运行到创建 SparkContext 对象时,那就开始初始化 SparkContext 对象了 |
| (5) | 在初始化 SparkContext 对象的时候,会创建两个特别重要的对象,分别是:1. DAGScheduler (RDD->Stage,—> taskSet) 2. TaskScheduler (SchedulerBackEnd->Actor) 【DAGScheduler 的作用】将 RDD 的依赖切分成一个一个的 stage,然后将 stage 作为 taskSet 提交给 DriverActor |
| 6 | 在构建 TaskScheduler 的同时,会创建两个非常重要的对象,分别是: 1. ClientActor: 向 master 注册用户提交的任务 ------------------ 2. DriverActor: 接受 executor 反向注册, 将任务提交给 executor |
| (7) | 当 ClientActor 启动后,会将用户提交的任务和相关的参数封装到 ApplicationDescription对象中,然后提交给 master 进行任务的注册 |
| (8) | 当 master 接受到 clientActor 提交的任务请求时,会将请求参数进行解析,并封装成 Application,然后将其持久化,然后将其加入到任务队列 waitingApps 中 |
| (9) | 当轮到我们提交的任务运行时,就开始调用 schedule(),进行任务资源的调度 |
| (10) | master 将调度好的资源封装到 launchExecutor 中发送给指定的 worker |
| (11) | worker 接受到 Master 发送来的 launchExecutor 时,会将其解压并封装到 ExecutorRunner中,然后调用这个对象的 start(), 启动 Executor |
| (12) | Executor 启动后会向 DriverActor 进行反向注册 |
| (13) | driverActor 会发送注册成功的消息给 Executor |
| (14) | Executor 接受到 DriverActor 注册成功的消息后会创建一个线程池,用于执行 DriverActor发送过来的 task 任务 |
| (15) | 当属于这个任务的所有的 Executor 启动并反向注册成功后,就意味着运行这个任务的环境已经准备好了,driver 会结束 SparkContext 对象的初始化,也就意味着 new SparkContext这句代码运行完成 |
3. action-job-stage-taskSet-DriverActor-launchTask-Executor-Rdd partition
| No. | Spark 任务的提交流程 |
|---|---|
| (16) | 当初始化 sc 成功后,driver 端就会继续运行我们编写的代码,然后开始创建初始的 RDD,然后进行一系列转换操作,当遇到一个 action 算子时,也就意味着触发了一个 job |
| (17) | driver 会将这个 job 提交给 DAGScheduler |
| (18) | DAGScheduler 将接受到的 job,从最后一个算子向前推导,将 DAG 依据宽依赖划分成一个一个的 stage,然后将 stage 封装成 taskSet,并将 taskSet 中的 task 提交给 DriverActor |
| (19) | DriverActor 接受到 DAGScheduler 发送过来的 task,会拿到一个序列化器,对 task 进行序列化,然后将序列化好的 task 封装到 launchTask 中,然后将 launchTask 发送给指定的Executor |
| (20) | Executor 接受到了 DriverActor 发送过来的 launchTask 时,会拿到一个反序列化器,对launchTask 进行反序列化,封装到 TaskRunner 中,然后从 Executor 这个线程池中获取一个线程,将反序列化好的 task 中的算子作用在 RDD 对应的分区上 |

spark1.x RPC AKKA
spark2.x RPC netty
Spark的任务提交和执行流程详解:
Checking if Disqus is accessible...