Spark Chap 7 内存模型和资源调优

最重要的5张图 - MapReduce编程案例 by 马中华
mapreduce 的 shuffle 是一通用的 shuffle (既每一个task最终都只会形成一个磁盘文件+一个索引)
spark 的4种 shuffle 就是在 mapreduce 的 shuffle 基础之上, 进行了某些动作的删减之后形成的
多种 shuffle 方案选择:
mapreduce:
partitioner, combiner, sort
spark:
可以在 4 种方案中选择使用其中的哪一种。 (就是对上面的 mapreduce shuffle 过程的)
各种全理论:
1) spark 的内存模型
堆内内存 + 堆外内存
执行内存 + 存储内存
静态内存模型 + 统一内存模型
动态占用机制
2) 资源调优
num-executors
executor-memory
total-executor-cores
spark.shuffle.memoryFraction
spark.storage.memoryFraction
…
spark-submit …
3) spark 的 shuffle
- HashShuffleManager
未优化版本
已优化版本
- SortShuffleManager
普通的机制
bypass机制
1. Spark 的 shuffle 调优
spark.shuffle.io.maxRetries
- 默认值:3
- 参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
- 调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
spark.shuffle.io.retryWait
- 默认值:5s
- 参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
- 调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
2. spark开发调优和DatSkew复习
2.1 开发调优
| 开发调优 1 ~ 3: 重复利用一个RDD | 重复利用一个RDD |
|---|---|
| (1). 避免创建重复 RDD | |
| (2). 尽可能复用同一个 RDD | |
| (3). 对多次使用的 RDD 进行持久化 | |
| 开发调优 4 ~ 6: 提高任务处理的性能 | 提高任务处理的性能 |
| (4). 尽量避免使用 shuffle 类算子 | |
| (5). 使用 map-side 预聚合的 shuffle 操作 | |
| (6). 使用高性能算子 | |
| (7). 广播大变量 (减轻网络负担) | |
| (8). 使用 Kryo 优化序列化性能 | |
| (9). 优化数据结构 |
总结: 如果说有某一个 RDD 会在一个程序中被多次使用,那么就应该不要重复创建,要多次使用这一个RDD (不可变的),既然要重复利用一个RDD,就应该把这个 RDD 进行持久化. (最好在内存中)
cache persist 持久化数据到磁盘或内存 unpersist
如何把持久化到磁盘或内存中的数据给删除掉呢?rdd.
2.2 Data Skew
数据如何分区? (随机,hash,范围)
| Data Skew | description |
|---|---|
| (1). DataSkew 发生的现象 | |
(2). DataSkew 发生的原理 |
> 数据分布不均匀 > 追求的目标: 数据分布要均匀 |
(3). 如何定位导致 DataSkew 的代码 |
> 某个 task 执行特别慢的情况 > 某个 task 莫名其妙内存溢出的情况 |
(4). 查看导致 DataSkew 的 key 的数据分布情况 |
> 测试 > 采样 |
3. spark 的内存管理宏观概述
spark 作为基于内存的分布式计算引擎, 其内存管理模块在整个系统中非常重要.
理解 spark 内存管理的基本原理,有助于更好的开发 spark 应用程序 和 进行性能调优.
- spark的内存模型
- spark的shuffle
- spark的资源调优
3.1 spark的内存模型
| No. | spark 的产生背景, spark 优于 mapreduce 的五大原因: |
|---|---|
| (1). | 减少了磁盘 IO |
| (2). | 提高并行度 |
| (3). | 避免重复计算 |
| (4). | 可选的 shuffle 和排序 |
| (5). | 提供了一个灵活的 内存管理策略 |
good Spark学习之路 (十一)SparkCore的调优之Spark内存模型
3.2 application 内存
| No. | 划分 | application 在运行的时候,会在哪些地方产生数据,需要存储在内存中呢? |
|---|---|---|
| 1. | 应用程序 | |
| 2. | 执行内存 | 全局变量,静态变量 |
| 3. | 执行内存 | task 在计算的时候, 数据在内存中(128M) (有的 ptn_data > 128 有的 < 128) |
| 4. | 执行内存 | mapPartitions (ptn_data => {}) for (element <- partition) code 执行过程中,使用的临时容器,临时变量 |
| 5. | 执行内存 | stage0 和 stage1 之间有 shuffle,这个将要进行 shuffle 的数据存储在何地? |
| … | 数据的分区数 |
|
| 6. | 存储内存 | 内存占用的大户: rdd.cache() 占用时间 长 + 多 |
| 7. | 存储内存 | 广播出来的大变量 sc,broadcast(list) list 会存储在所有 executor 内存中 |
| … | 一种合适的内存管理策略,可以提升内存利用率,提高Task执行的成功率 |
3.3 Spark 内存模型概述
在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种 JVM 进程
Driver主控进程,负责创建 SparkContext,提交 Spark Job,并将作业转化为计算任务(Task),在各个 Executor 进程间协调任务的调度
Executor负责在工作节点上执行具体的 计算 Task,并将结果返回给 Driver,同时为需要持久化的 RDD 提供存储功能[1]。由于 Driver-memory 1G 的内存管理相对来说较为简单,本文主要对 Executor 的内存管理进行分析,下文中的
Spark 内存均特指 Executor 的内存。
| Spark 的应用程序2种进程 |
|---|
| driver: 主控进程,必须保证不能出错, 而且也只有一个 |
| executor: task 的执行载体,数量也很多 |
| 侧重点: executor 上的内存管理 |
| 执行 task 过程中会产生哪些数据呢? 2 3 4 5 |
spark 帮助我们把应用程序执行构成当中所占用的内存分成 2 个方面:
- 执行内存 2 3 4 5 必须的
- 存储内存 6 7 可有可无
3.4 Spark 把内存做分类的目的
假如给每一个 executor 分配的内存是
8G: 执行内存: 1G, 存储内存 7G
2G: 执行内存: 1G, 存储内存 1G
| 假如给每一个 executor 分配的内存是 8G |
|---|
| (1). 当这个 executor 启动一个 task 执行计算的时候,处理的数据量是 2G |
| (2). 当这个 executor 启动一个 task 执行计算的时候,处理的数据量是 6G |
结论: 同一个程序在执行不同量级的数据的计算的时候,每个 task 执行的内存所占用的资源其实差不多一致
数据分区的存储
3.5 Spark内存的整体划分
又分为2种不同类型的内存划分:
| No. | spark 能利用的内存有2个区域 |
|---|---|
| 1. | (executor内存) JVM 内部 的 On-heap Memory (对于JVM来说叫做 堆内存) |
| 2. | (executor外部) JVM 外部/操作系统 的 Off-heap Memory |
这2个区域,又都分为2个区域:
1 | public class Test1 { |
正常的情况下,一个 JVM 进程中的线程是没法从操作系统中申请内存的
只能从 JVM 中申请内存
但是现在spark的task(一个线程)就可以从操作系统,也就是说JVM之外,申请内存使用,而且还是所有的task公用的.
有什么好处?
spark 的程序中,上面缓存的RDD,在这个应用程序中的任何地方都可以访问
4. spark 的静态内存模型和统一内存模型详解 + 资源调优

spark 的2种内存管理方式:
1). spark 1.x 静态内存模型
执行内存和存储内存 相互之间
不能占用
2). spark 2.x 统一内存模型
执行内存和存储内存 相互之间
能占用
内存管理接口: MemoryManager
- StaticMemoryManager
- UnifiedMemoryManager
方法: 重要的方法有 6 个:
3个是申请内存的, 3个是释放内存的
以上这3个申请和3个释放内存的方法,其实就是对申请到的总内存进行一种逻辑上的管理规划
堆内内存 和 堆外内存 是真是存在的一个内存区域
执行内存和存储内存,都是堆内和堆外内存的一个逻辑区划的概念.

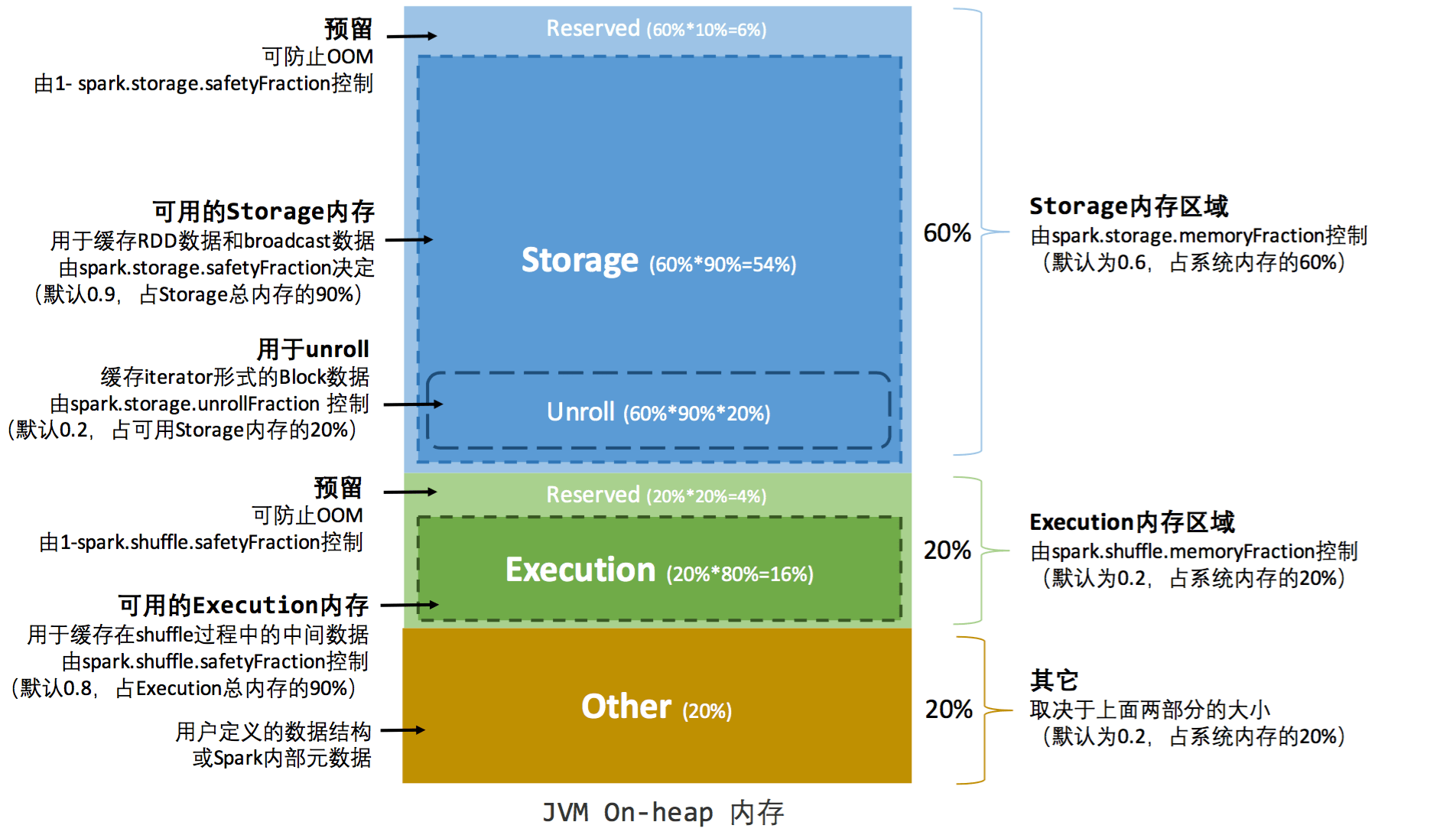
4.1 spark 的静态内存模型
静态内存管理图示——堆内
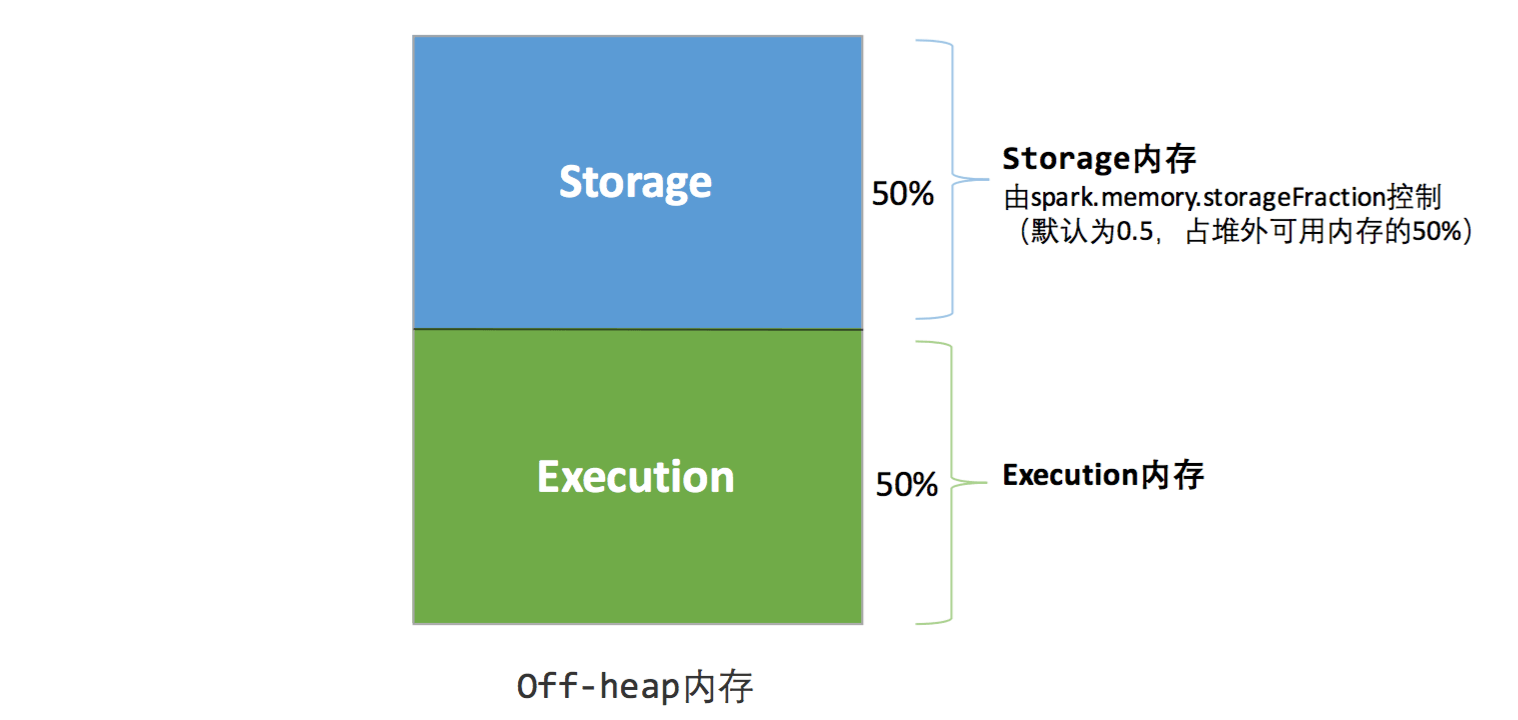
静态内存管理图示——堆外
4.2 统一内存模型
统一内存管理图示——堆内
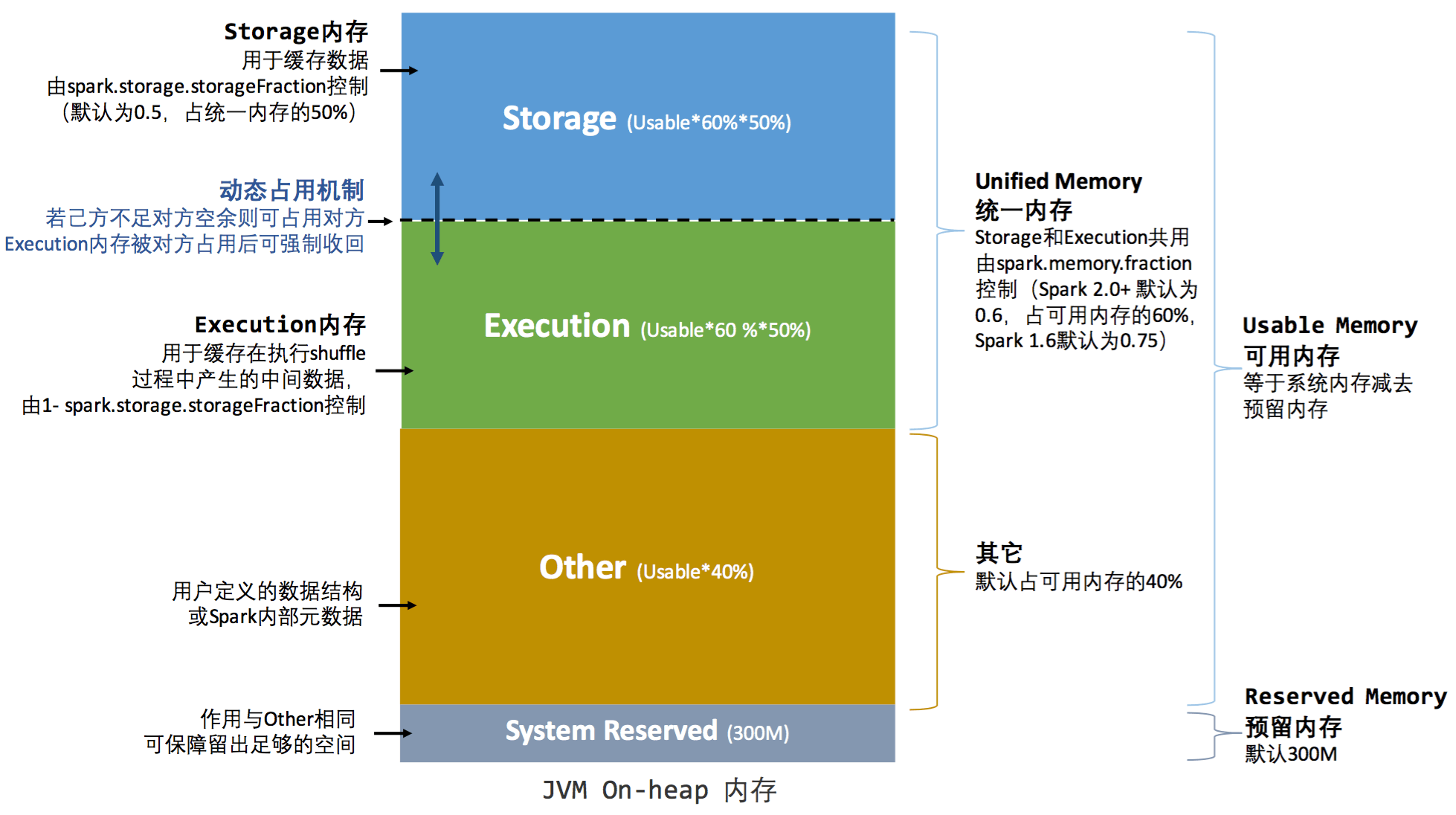
Execution 占用 Storage 是不会归还的, 反之 要归还
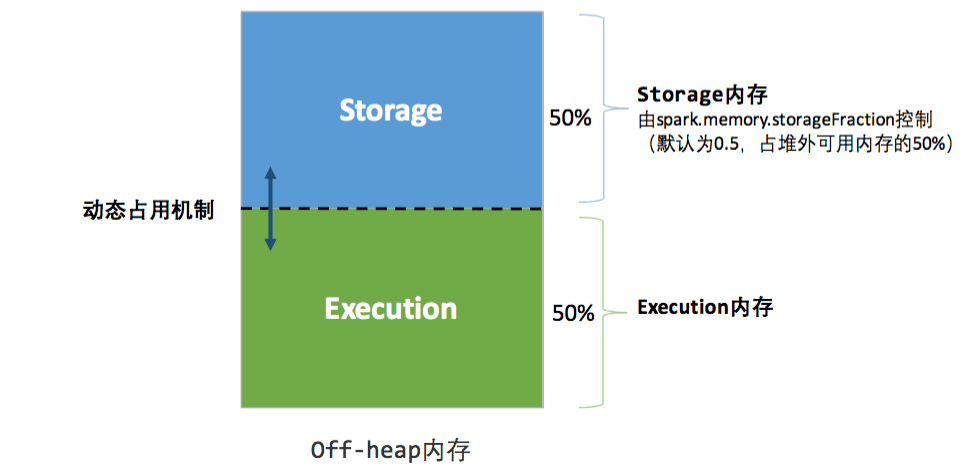
统一内存管理图示——堆外
application 中的 job 的执行: FIFO
把 YARN 的资源分拆成多个不同的队列
每个队列中的任务的执行是顺序的 FIFO 执行
整个程序到底有多少个 task? num-executors
如果现在一个 executor 的 task 数量
一个 executor 分配 3~5个 cpu cores.
5. 资源调优 2
| 资源调优 params | description 参数调优建议 |
|---|---|
| (1) num-executors | 一个 executor 就是一个进程, 50~100个左右的Executor进程比较合适 |
| (2) executor-memory | 每个Executor进程的内存设置4G~8G较为合适 |
| (3) total-executor-cores | Executor的CPU core数量设置为2~4个较为合适 每个进程可以使用多少个 cpu core,一个executor 启动 10 个task |
| driver-memory | Driver的内存通常来说不设置,或者设置1G左右应该就够了 |
| spark.default.parallelism | 该参数用于设置每个stage的默认task数量。这个参数极为重要 Spark作业的默认task数量为500~1000个较为合适。很多同学常犯的一个错误就是不去设置这个参数,那么此时就会导致Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。 设置该参数为num-executors * executor-cores的2~3倍较为合适 |
| (4) spark.shuffle.memoryFraction | |
| (5) spark.storage.memoryFraction | |
| … | … |
| spark-submit … |
如果 master 是 local: 默认的分区数是 1个,而且没有 executore
如果 master 是 spark: 默认的分区数是 2个 min(defaultMinPartitions,2),有 executore
一个 spark 应用程序:
500个task
50个executor
每一个 executor 执行 10 个 task 左右
每一个 executor 分配 3~5个
总 cpu core 数: 150 ~ 250
每一个 executor 分配的内存是: 2G
driver程序分配的内存: 2G整个应用总消耗:50*2 + 2 = 102 内存
每 1 个 stage 中的到底有多少个 task 由谁决定?
划分 stage 的标准:
shuffle 算子,宽依赖在一个stage中是有可能有
多个RDD的每一个 stage 中的 task 总数, 是由这个 stage 中的最后一个 RDD 的分区数来决定的.
spark 从 hdfs 中读取数据,使用的方式,默认情况下依然是 TextInputFormat
默认情况下 mapreduce 中数据读取规则是由
TextInputFormat 和 LineRecordReader 决定
默认情况下,其实就是 1个block 1个task每个元素的读取方式依然是逐行读取形成为一个元素
mapper: key, value
rdd: valueRDD[String]
spark.storage.memoryFraction
spark.shuffle.memoryFraction
资源参数参考示例
1 | ./bin/spark-submit \ |
一般机器: 32/64cpu, 64G/128G/256G
60cpu core, 240G 内存。 另外16G内存给系统运行用.
每一个 cpu core 4G 内存
每一个 executor 要分配2~3个cpu core, 分配内存: 8~12G
每一个application大概是: 100个executor
6. mapreduce的shuffle复习
key, value
kvbuffer:
ptn, key, value
ptn+key
Reference
- 从一个sql任务理解spark内存模型
- Apache Spark 内存管理详解
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型
- 云课堂 SparkSQL 的数据源操作
- 大数据资料笔记整理
- Spark性能优化指南——高级篇
- Spark性能优化指南——基础篇
Checking if Disqus is accessible...